
We know Microsoft confirmed it helps. But the mechanism? That's where things get interesting.
TL;DR
- Schema reinforces, not replaces. AI systems don't simply read schema as content. Experiments show schema-only pages are completely ignored by ChatGPT, Gemini, Claude, and Perplexity.
- It works best alongside visible content. In controlled tests, pages with schema + matching visible content led to more complete extraction than identical pages without schema.
- Bottom line: Schema can't replace your content, but it highlights and reinforces it, leading to better retrieval and more grounded responses. It makes your pages more machine-legible for AI systems.
- What to do: Put important information in your page content first. Use schema to reinforce structured attributes.
The part everyone agrees on.
When you ask ChatGPT or Perplexity to search the web, it's not simply reading your schema markup the way Google reads it for rich snippets.
Most people in SEO know that part intuitively. But the conversation usually stops there, replaced by vague claims that schema "helps AI understand your content."
Microsoft, creator of Bing and a key data source for ChatGPT, confirmed this in October 2025. Krishna Madhavan, Principal Product Manager, wrote that "schema is a type of code that helps search engines and AI systems understand your content" [1].
That's useful confirmation. But it doesn't tell us when the schema actually matters. Or how it gets used.
That's what I want to dig into here. I'll be doing some mental deduction based on how these systems are built.
First, a quick framework.
If you've read Ida Silfverskiöld's breakdown of AI chatbot architecture, you know she splits the process into two phases: discovery and retrieval [2].
Discovery is finding candidate URLs. This is where traditional search engines like Bing still do the heavy lifting. They narrow the entire web down to a manageable set of pages worth looking at.
Retrieval is what happens next. The system fetches those pages, breaks them into chunks, and figures out which pieces actually answer the user's question.
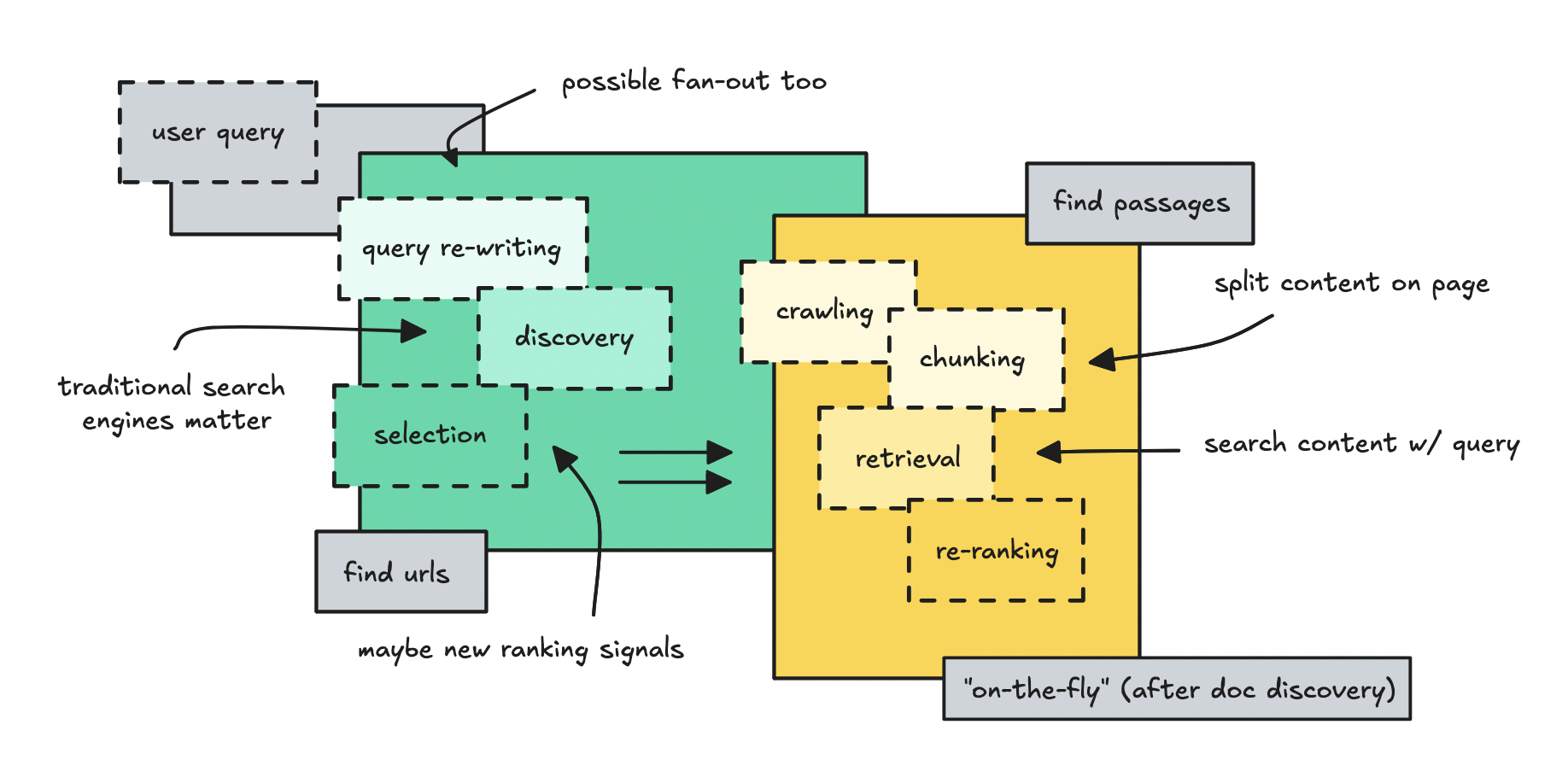
For discovery, schema probably doesn't change much. That phase still relies on traditional SEO signals: authority, backlinks, crawlability. Schema helps you earn rich results in traditional search, but that's not new or AI-specific.
Retrieval is where things get interesting. Most people don’t know this, but it's not one step. It's a sequence: crawl the page, parse, and chunk the content, then search those chunks for the best answer. Schema markup could potentially help at different points in this sequence.
Let's start by understanding why structured data matters more now. Then we'll explore where schema might fit in the retrieval process.
The shift from keywords to entities: why structure matters now.
Traditional SEO cares a lot about matching exact phrases. If someone searched "best running shoes for bad knees," you'd optimize for that exact string in your title, headers, and body copy.
That's changing. AI systems now think in terms of entities and relationships. A messy human question like "what should I get for my dad who runs but has knee problems" gets understood as structure: there's a person (runner with knee issues), a product need (footwear with cushioning and support), and a context (gift-giving).
The AI understands: who (a runner with knee problems), what (shoes with specific support features), and why (a gift). Those are entities and relationships, not keyword matching.
Schema markup speaks this language natively. A Product schema declares:
- Here's an entity (the product),
- Here are its attributes (price, availability, rating),
- And here's how it relates to other things (brand, seller, reviews).
These are grounded relationships and concepts, not just keywords floating in prose.
Think of it like the difference between reading a book with no chapter titles versus one with a detailed table of contents. Both contain the same information. One is much faster to navigate.
If AI systems can use schema as a structural guide, they should be able to navigate content faster and more accurately. And because the relationships are explicit rather than inferred, there's less room for hallucination.
That's the why. Now let's explore how schema might actually get used.
Does schema get flattened into tokens like visible content?
Here's a question worth asking:
“What if AI systems just treat schema like any other text on the page?”
In standard RAG (Retrieval Augmented Generation) pipelines, content gets flattened into text, then embedded as vectors for semantic search. If schema gets the same treatment, your Product schema becomes something like:
"name ProBook 15 price 1299 offers priceCurrency USD availability InStock"
If that's what happens, schema provides almost no incremental value. The visible text on your page already says "The ProBook 15 costs $1,299." Flattening the schema just creates a near-duplicate.
There's some evidence this isn't how it works.
Multiple experiments have tested what happens when information exists only in schema markup, with no visible HTML counterpart.
The results are consistent: AI systems fail to extract it.
Julio C. Guevara's 2025 tests created two product pages for fictional products. One had visible HTML plus schema. The other had schema only, with no visible text. When researchers asked ChatGPT and Gemini extraction questions (price, SKU, colors), the LLMs could only retrieve information from the page with visible text. The schema-only page failed completely [3] [4].
SearchVIU ran an even more rigorous version in late 2025, testing eight different scenarios across five AI systems (ChatGPT, Claude, Gemini, Perplexity, and Google AI Mode). In one of their tests, they placed a product price exclusively in JSON-LD schema, not visible anywhere on the page. The result: zero out of five systems extracted it. Not one. They also tested hidden Microdata and hidden RDFa with the same result [5].
This tells us something important: If schema is used in the process at all, it is probably not being read the same way as the “visible content” on the page. If AI systems were tokenizing schema markup alongside visible text, they would have found the schema-only information. They didn't.
My read: schema probably isn't flattened and tokenized alongside visible content. If it were, the schema-only experiments would have worked.
So if schema isn't treated like regular text, how is it used?
If schema is processed differently, when does that happen?
Let's think through the retrieval sequence:
- Crawl — fetch the HTML
- Parse — extract and understand the content structure
- Chunk — break content into smaller pieces
- Embed/Match — semantic search to find relevant chunks
- Re-rank — refine the results
- Synthesize — generate the final answer
If schema isn't being tokenized like visible content, it's probably being leveraged earlier in this sequence: likely in parsing and chunking steps, before embedding happens.
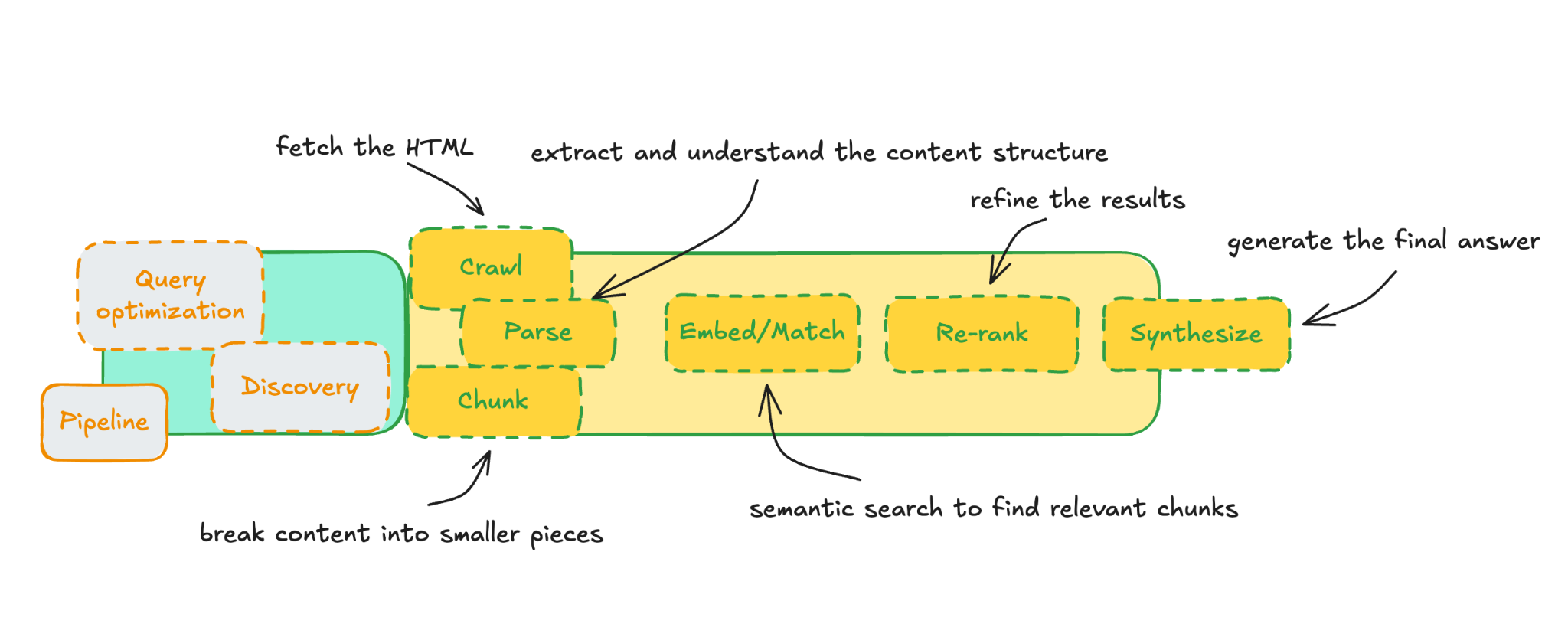
Here are a few possibilities for what schema enables at each stage:
1. Parsing (Step 2)
Schema could help the system decide what to do with a page right after fetching it.
Filtering. The system might use schema types to narrow candidates before semantic matching. A product query might prioritize pages with Product schema. A "how to" query might favor pages with HowTo schema.
This happens upstream of embedding, the system is deciding which content is worth processing further. We can think of it similar to a table of contents for a book.
Direct extraction. For certain factual queries, the system might bypass semantic search entirely and pull from structured fields.
"What's the price of the iPhone 16 Pro?" may not need embedding similarity. It needs a simple lookup: find Product schema, return the price field.
If this is happening, schema lets the system jump straight from parsing (step 2) to synthesis (step 6).
Entity and relationship mapping. Schema with @graph and @id patterns pre-declares how entities on a page connect to each other. Without schema, the system has to infer: "This FAQ section is probably about the product mentioned above, which is probably sold by the company whose name is in the header." That's a lot of guessing.
With schema, the relationships are explicit: the FAQ is about the product, which is provided by the organization. Schema potentially hands over something like a mini knowledge graph instead of forcing the system to interpret the relationship from visible content.
All three of these are fairly standard practices in traditional RAG systems. Filtering by metadata, querying structured fields directly, and using relationship graphs are well-established approaches. Although “JSON-LD data store” is not directly mentioned in RAG literature, the way schema markup works fit naturally into this architecture: it provides the structured metadata layer that these systems already know how to use.
2. Chunking guidance (Step 3)
Schema could also inform how visible content gets divided into pieces.
Microsoft's October 2025 guidance describes how AI systems process content:
"AI assistants don't read a page top to bottom like a person would. They break content into smaller, usable pieces, a process called parsing. These modular pieces are what get ranked and assembled into answers" [1].
The key insight: AI doesn't read linearly. It chunks. And schema can guide that chunking process.
If FAQPage schema exists, the system knows to treat each Q&A pair as a discrete unit rather than splitting a question from its answer. If Product schema exists, it knows product attributes should stay together rather than being scattered across chunks.
Better chunking leads to better matching downstream. Schema provides structural hints that help the system chunk intelligently.
This is also a standard RAG pattern. Dell Technologies describes "schema-aware chunking" that "recognizes that structured data's meaning comes from its relationships and patterns" and "preserves schema information... as metadata with each chunk" [9].
Stack Overflow's own RAG implementation uses the same principle: "We configured our embedding pipeline to consider questions, answers, and comments as discrete semantic chunks. Our Q&A pages are highly structured and have a lot of information built into the structure of the page" [10].
These examples use document structure and data schemas, not JSON-LD specifically. But the principle is the same: structural metadata guides chunking decisions. JSON-LD schema markup could serve this function, providing machine-readable hints about how content should be grouped.
3. Embed/Match and Re-rank (Step 4 and 5)
After chunking, the system needs to find chunks that best answer the query. This typically involves embedding both query and chunks into vector space, then finding the closest matches.
Does schema help here? Possibly.
As we mentioned in direct extraction above, some RAG systems preserve JSON structure and query it directly using something like JSONPath: "find the object where @type equals Product, return the price field." If AI search platforms do this, schema would be extremely valuable, it lets the system extract precise facts without relying on semantic similarity.
Based on the experiments and standard RAG practices, we can reasonably infer that schema's value is concentrated in steps 2-3 (parsing and chunking).
The schema-only extraction failures suggest schema isn't being embedded alongside visible content. And the established RAG patterns: filtering, direct extraction, relationship mapping, schema-aware chunking, all operate before or alongside the embedding phase, facilitating natural language understanding.
Evidence from a controlled experiment.
So far, this has been theory. Let's look at some actual evidence.
Here’s where it gets interesting: there's evidence schema helps AI systems extract more from your visible content.
AISO ran a controlled experiment in early 2025. They created two identical websites about a fictional company called TechFlow Solutions. Same content. Same design. Same visible information: including product ratings like "4.8/5 stars (2,100+ reviews)" displayed on the page.
The only difference: one site had comprehensive schema markup, one didn't [6].
Then they asked ChatGPT the same questions about both sites and compared the responses.
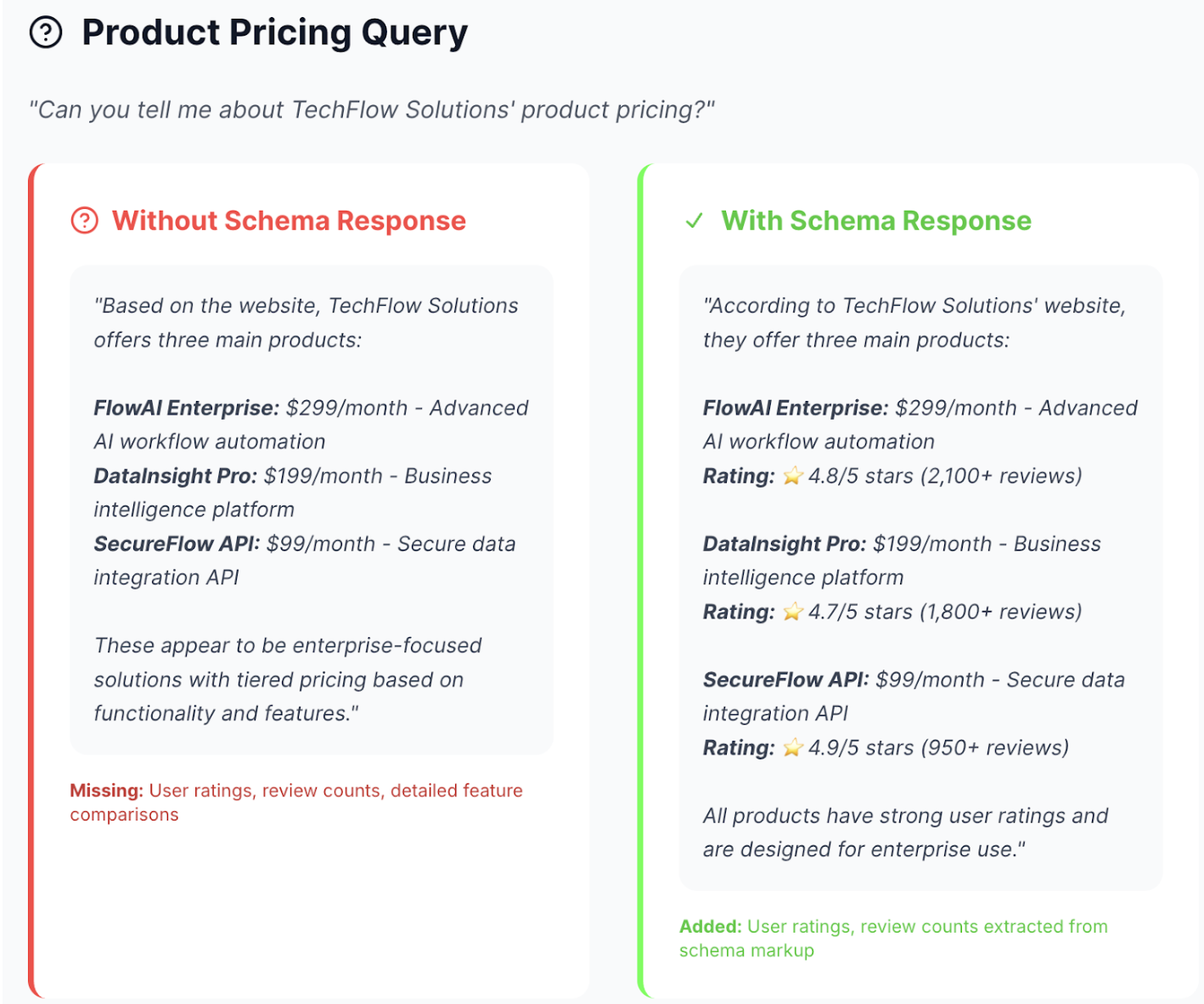
The results were interesting. When asked about product pricing:
Without schema: ChatGPT returned basic pricing info: product names and monthly costs. It missed the ratings entirely, even though they were visible on the page.
With schema: ChatGPT returned the same pricing plus user ratings (4.8/5 stars from 2,100+ reviews) and review counts.
Here's the key insight: the ratings were visible on both pages. The schema version didn't have hidden data the other lacked. What changed was whether ChatGPT noticed that information and included it in the response.
Similar patterns appeared across other queries. Certifications like ISO 27001 and SOC 2 appeared more reliably when schema was present. The schema version maintained better professional boundaries (less personal information surfaced inappropriately). Overall, AISO scored the schema responses 30% higher on accuracy and completeness.
This suggests schema could work like an “attention mechanism.” It doesn't provide new information to the AI, but it helps the AI recognize which pieces of visible content are structured, important, and worth extracting.
Think of it like highlighting. Both pages have the same text. But the schema version has certain information structurally emphasized in a way the AI can recognize. The visible content and schema markup reinforce each other.
But here's what makes it interesting: by passing specific URLs to ChatGPT, the experiment effectively intercepted the pipeline after discovery.
ChatGPT wasn't choosing which pages to look at (so no discovery needed), it was given two specific URLs and asked to extract information from them.
That means the experiment is testing the retrieval steps specifically: crawling, parsing/chunking, and response synthesis.
And on that question, the evidence suggests: schema affects what gets noticed and extracted, even when the underlying content is identical.
What we know vs. what we're inferring.
Let me lay out the confidence levels:
Confirmed:
- Microsoft says schema helps their LLMs understand content [1]
- Fabrice Canel (Microsoft/Bing) has said schema helps AI-driven search since at least 2023, reaffirmed in March 2025 [7]
- Google says structured data provides "explicit clues about the meaning of a page" [8]
Supported by multiple experiments (limited scale):
- Schema-only content failed extraction in tests by Guevara (2025) and SearchVIU (2025) [4][5], which suggests schema is likely not tokenized like visible content
- Schema + matching visible content appears to improve extraction compared to visible content alone (AISO experiment) [6]
Likely (strong inference):
- Schema is probably processed during parsing, not flattened into embeddings, potentially enabling filtering, direct extraction, and chunking guidance
- Schema could work as an attention/highlighting mechanism during parsing, helping AI systems notice and prioritize structured information in visible content
- The value is in recognition, extraction and structured understanding, not as a standalone data source
Unknown:
- Exactly how ChatGPT, Perplexity, or Gemini process schema internally
- Whether different schema types have different impacts
- Whether @graph relationships are processed differently than disconnected schema blocks
- The exact mechanism by which schema improves extraction rates
What to do with this.
Given the variables, here's what makes sense:
Don't rely on schema alone. The experiments are clear: schema-only content fails. Everything important also needs to be in your visible HTML.
Use schema to reinforce your most important information. The AISO experiment showed schema helps AI systems notice visible content. If you want ratings, certifications, or product details to surface in AI responses, make sure they exist in both visible content AND schema markup. The double-confirmation helps.
Focus on schema types with structured attributes. Ratings, reviews, certifications, pricing, these are the types that showed the clearest benefits in testing. Schema that merely duplicates prose ("description:" "We are a great company...") probably adds less value.
Use @graph with @id relationships. Connect your entities explicitly. If the system does any kind of relationship mapping, explicit connections should help.
Implement schema for the confirmed benefits. Rich results still matter for traditional search. And the parsing/attention benefits in AI search are now supported by real experiments, not just theory.
The honest position:
We're recommending schema because 1. Microsoft confirmed it helps with understanding, 2. the architecture suggests it helps with parsing, and 3. empirical experiments show it affects what gets extracted. Based on our research, schema appears to work as a highlighting mechanism for AI systems. It helps them recognize and extract structured information from your visible content. It's not a ranking signal. It's not a secret data source. It's a way to make your content more machine-legible.
Frequently asked questions
Q: Does schema markup help my content appear in ChatGPT and other AI search engines?
Based on experiments and Microsoft's confirmation, schema appears to help during the parsing and chunking phases of AI retrieval, helping AI systems notice and extract structured information from your visible content.
Q: Can I put important information only in my schema markup?
We don’t suggest you do so. Multiple experiments show that schema-only content fails extraction across all major AI platforms (ChatGPT, Claude, Gemini, Perplexity, Google AI Mode). Everything important should appear in your visible HTML first. Schema enhances visible content; it doesn't replace it.
Q: What types of schema are most effective for AI search?
Schema types with structured attributes show the clearest benefits: ratings, reviews, certifications, and pricing. Focus on attributes that provide discrete, extractable facts.
Q: Does schema help with discovery or retrieval in AI search?
Primarily retrieval. Discovery (finding candidate URLs) still relies on traditional search engine indexes like Google and Bing. Schema's value appears to be in the retrieval phase, most likely during parsing and chunking, helping AI systems process and extract from your content more effectively.
Q: How is schema different from regular page content for AI systems?
Experiments suggest schema is not embedded as retrievable content like visible text. Instead, it likely functions as metadata that guides parsing, filtering, and chunking decisions. Think of it as structural hints that help AI systems navigate your content, similar to a table of contents.
Q: Should I use @graph and @id in my schema markup?
Ideally yes, if you have multiple related entities on a page. @graph with @id relationships explicitly connects entities (e.g., a product, its reviews, and the organization selling it). This could help AI systems understand relationships without having to infer them from text.
Reference
[1] Krishna Madhavan, "Optimizing Your Content for Inclusion in AI Search Answers," Microsoft Advertising Blog, October 2025.
[2] Ida Silfverskiöld, "The Architecture Behind Web Search in AI Chatbots," Towards Data Science, December 2025.
[3] LinkedIn posts by Mark Williams-Cook and Julio C. Guevara.
[4] Julio C. Guevara, schema-only extraction tests, 2025. Referenced in Search Engine Roundtable and generative-engine.org.
[5] SearchVIU, "Schema Markup and AI in 2025: What ChatGPT, Claude, Perplexity & Gemini Really See," December 2025.
[6] AISO, "Schema Markup vs No Schema: A Real ChatGPT Experiment Reveals Surprising Results," January 2025.
[7] Fabrice Canel, SMX Munich presentation, March 2025. Referenced in Schema App coverage.
[8] Google Search Central, "Structured Data Documentation."
[9] Dell Technologies, "Chunk Twice, Retrieve Once: RAG Chunking Strategies Optimized for Different Content Types," Dell Technologies Info Hub.
[10] Stack Overflow, "Breaking up is hard to do: Chunking in RAG applications," Stack Overflow Blog, December 2024.

